

Continuando con la exploración de los diversos usos para servicios de Azure AI.
En este post, utilizaremos el servicio de Computer Visión para realizar el analisis de imagenes a través de una aplicación React que estaremos implementando en el servicio de Azure Static Web App.
Esta potente herramienta utiliza aprendizaje automático para analizar imágenes y extraer información rica y contextual.
Repositorio: https://github.com/mdiloreto/analyze-and-generate-images-with-Azure-AI2
Demo de la App en Azure Static Web App
Luego de desplegar nuestra aplicación de React en una Static Web App (SWA) de Azure utilizando GitHub Actions podremos ingresar a través de la url publica:
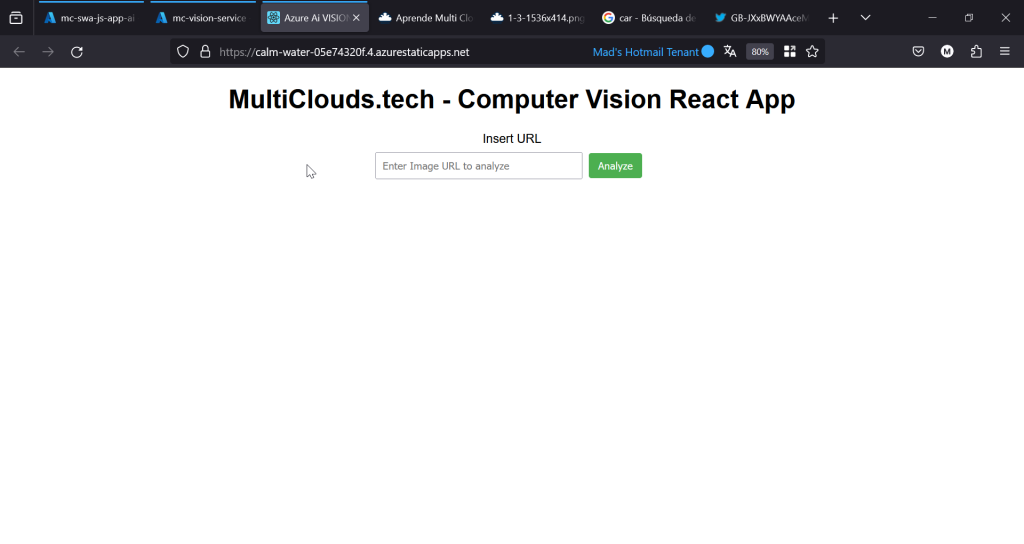
Ingresamos la URL de una foto en el input value y hacemos click en “Analyze”:

Ejecutar el proceso de Loading mientras se hace la consulta de la API:
- Imagen utilizada: https://pbs.twimg.com/media/GB-JXxBWYAAceMp?format=jpg&name=medium

Y posteriormente arrojará el resultado:
- Mostrando la Imagen:

- Arrojando la Descripción y los Tags:

- Los Read Text elements (OCR):

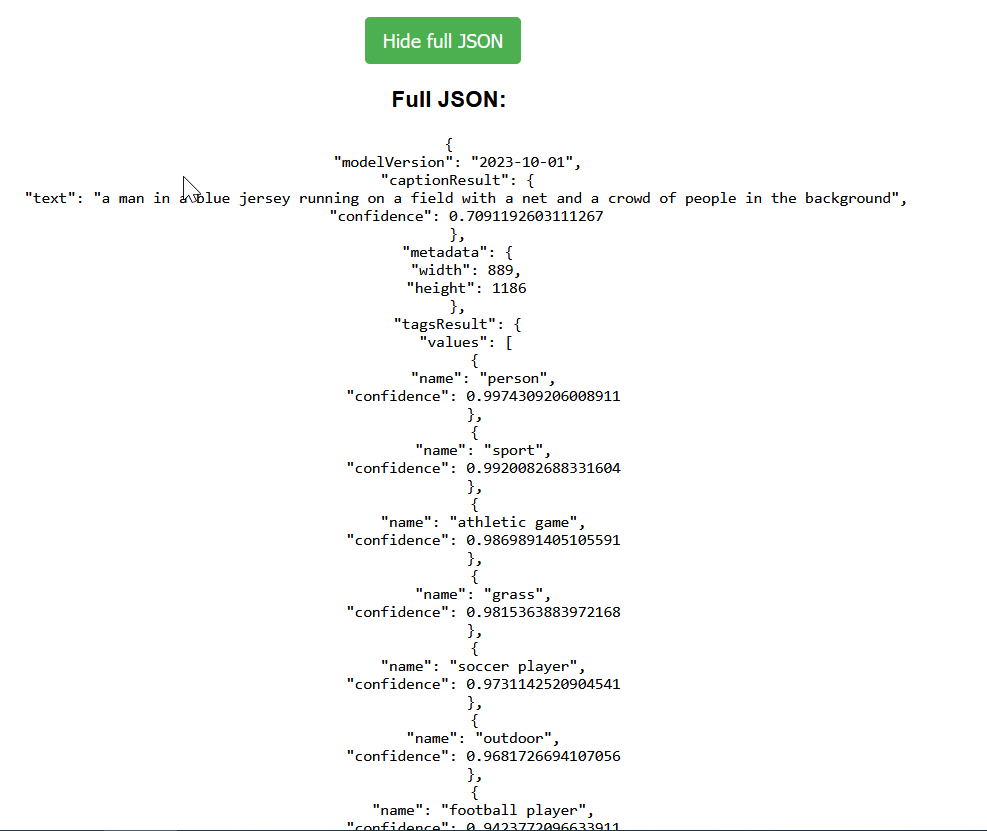
Y ademas nos da la posibilidad de ver la respuesta completa en formato JSON:
¿Qué es Azure Computer Vision?

Azure Computer Vision es parte de la familia de servicios cognitivos de Azure AI y se especializa en el procesamiento y análisis de imágenes y videos. Con la capacidad de detectar y clasificar contenido visual, Computer Vision transforma las imágenes en datos comprensibles que pueden impulsar decisiones y automatización de procesos. Entre sus funcionalidades destacan:
- Detección y análisis de objetos y escenas: La API puede identificar y localizar objetos dentro de una imagen, brindando no solo el tipo de objeto detectado, sino también la posición específica del mismo. Esto resulta útil para aplicaciones de conteo, seguridad y gestión de inventario, por ejemplo.
- Lectura y extracción de texto: Utilizando OCR (reconocimiento óptico de caracteres), Computer Vision es capaz de leer texto en una variedad de idiomas, incluso en condiciones de baja luminosidad o sobre superficies irregulares. Esto abre posibilidades en la digitalización de documentos y la automatización de entrada de datos.
- Análisis facial: el análisis facial puede identificar edades aproximadas, emociones y otros atributos a partir de imágenes de rostros humanos.
- Descripción de imágenes: Probablemente una de las características más impresionantes es la capacidad de generar una descripción textual de una imagen, similar a cómo una persona podría describirla. Esto no solo es útil para la creación de contenido accesible (como en el caso de personas con discapacidad visual), sino también para el análisis de contenido en redes sociales u otras plataformas.
¿Cómo podemos utilizarla?
Esta es una de las principales caracteristicas de este servicio: su utilización es muy simple, solo tenes que llamar a la API.
En este caso estaremos realizando una llamada a la API en su versión 4.0 para la función de Analisis de Imagen. Dejo debajo el link de referencia:
Para llamar a la API debemos realizar un HTTP POST request al endpoint de nuestro servicio especificando los parametros en la URL:
https://<endpoint>/computervision/imageanalysis:analyze?api-version=2023-10-01&features=tags,read,caption,denseCaptions,smartCrops,objects,people<endpoint>: Representa el punto de acceso específico del servicio de Computer Vision que se te asignó al crear el recurso en Azure. Este endpoint varía según la región y la instancia de servicio que hayas configurado./computervision/imageanalysis:analyze: Es el path que indica el recurso específico de la API que se va a utilizar. En este caso,computervision/imageanalysis:analyzese refiere a la operación de análisis de imágenes dentro del servicio de Computer Vision.?api-version=2023-10-01: Es un parámetro de consulta que especifica la versión de la API que se desea utilizar. La versión2023-10-01se refiere a una versión específica de la API que soporta ciertas características.&features=tags,read,caption,denseCaptions,smartCrops,objects,people: Este es otro parámetro de consulta que indica las características de análisis visual que se quieren activar para la imagen.
Tipos de Analisis de Imagen en la API 4.0
Cada Feature ofrece diferentes tipos de información:
tags: Devuelve palabras clave o etiquetas que son relevantes para el contenido de la imagen.read: Utiliza OCR (Optical Character Recognition) para leer el texto visible en la imagen.caption: Proporciona una descripción textual concisa de la imagen.denseCaptions: Ofrece descripciones detalladas para las regiones prominentes de la imagen.smartCrops: Proporciona sugerencias de recorte de imágenes basadas en aspectos visuales importantes.objects: Detecta objetos dentro de la imagen, incluyendo su ubicación aproximada.people: Identifica a las personas que aparecen en la imagen, incluyendo su ubicación aproximada.
Alta del servicio Computer Vision en Azure
En primer lugar buscaremos “Compute Vision” en nuestro buscador global de Azure:
Ingresaremos al servicio y haremos click en “+Create”
Popularemos la información Basica del Asistente:
- En este caso, estamos seleccionando el servicio Standard, pero para pruebas podrán utilizar el Free Tier sin problemas.
En este caso no realizaremos ninguna configuración de red por motivos de la demo, pero recomiendo mantener los servicios dentro de nuestras redes privadas en la mayoría de los casos por seguridad:
El resto de las configuraciones las mantenemos por defecto. Y damos click a “Review + Create”.
Nuestro Servicio de Compute Visión se creará en nuestra subscripción:
Key y Endpoint
Lo primero que necesitamos para utilizar nuestro servicio de Compute Vision en Azure es el Endpoint y una API KEY.
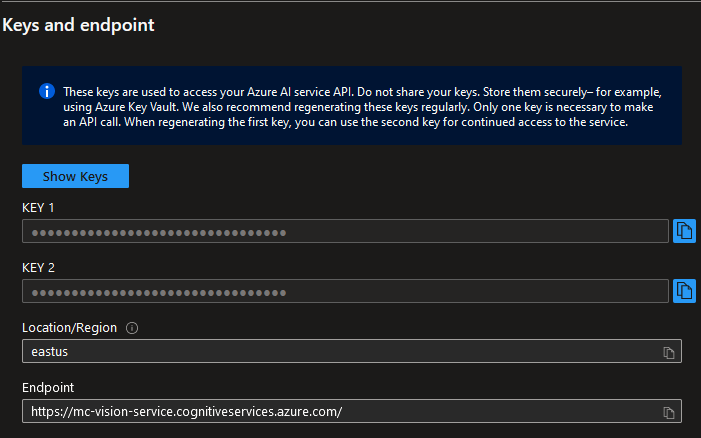
Debemos tomar nota y guardar esta información de manera privada. No debemos hardcodear ninguno de estos datos en nuestro codigo, como veremos mas adelante utilizaremos variables de entorno. En este caso guardando la información en los Secrets de GitHub Actions.
Guardar las variables en Git Hub Actions
En primer lugar les recomiendo realizar un fork o clonado del repositorio y almacenarlo en un repositorio personal de GitHueb Actions.
Repositorio: https://github.com/mdiloreto/analyze-and-generate-images-with-Azure-AI2
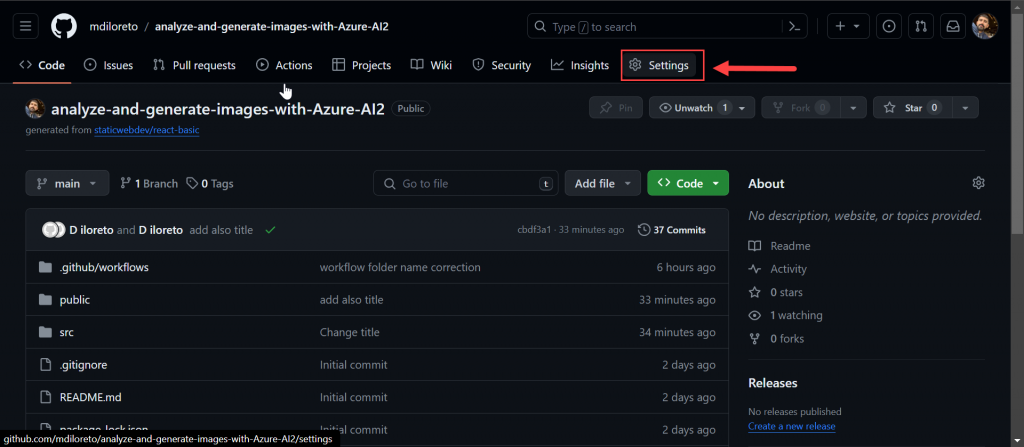
En primer lugar ingresaremos a nuestro repo y haremos click en “Settings”:
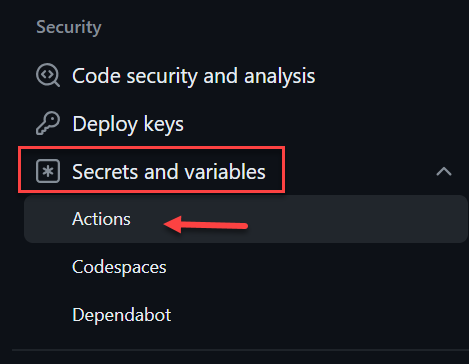
En la sección de Settings de Seguridad, haremos click en “Secrets and Variables” y haremos click en “Actions”:
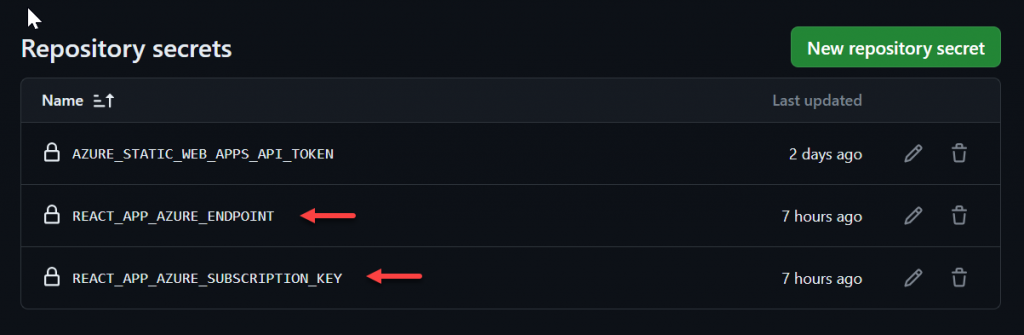
Y agregaremos las variables:
- REACT_APP_AZURE_ENDPOINT.
- REACT_APP_AZURE_SUBSCRIPTION_KEY.
Luego estas variables las podremos pasar a través de nuestro Workflow de GitHub Actions.
Paso de variables de entorno a través de Workflow de GitHub Actions
Utilizaremos el yaml del Workflow de GitHub Actions para pasar las variables de entorno de nuestro Endpoint y Key:
# Environment variables available to all jobs and steps in this workflow
env:
REACT_APP_AZURE_SUBSCRIPTION_KEY: ${{ secrets.REACT_APP_AZURE_SUBSCRIPTION_KEY }}
REACT_APP_AZURE_ENDPOINT: ${{ secrets.REACT_APP_AZURE_ENDPOINT }}Llamada a la API con JavaScript React
Estaremos utilizando el siguiente codigo para consumir nuestro servicio de Computer Vision de Azure:
// azure-image-analysis.js
const subscriptionKey = process.env.REACT_APP_AZURE_SUBSCRIPTION_KEY;
const endpoint = process.env.REACT_APP_AZURE_ENDPOINT;
async function analyzeImage(imageUrl) {
// API version and query parameters for the features you want to analyze
const apiVersion = '2023-10-01';
const features = 'tags,read,caption';
const response = await fetch(`${endpoint}computervision/imageanalysis:analyze?api-version=${apiVersion}&features=${features}`, {
method: 'POST',
body: JSON.stringify({ url: imageUrl }),
headers: {
'Ocp-Apim-Subscription-Key': subscriptionKey,
'Content-Type': 'application/json'
}
});
if (!response.ok) {
throw new Error('Image analysis failed:', response.statusText);
}
return response.json();
}
export default analyzeImage;
- Como podemos ver tomamos las variables de entorno pasadas a través de GitHub Actions Secrets.
Luego lo importamos al codigo principal de js:
import analyzeImage from './azure-image-analysis';Y llamamos a nuestra función al hacer click en el boton de Analyze:
const handleAnalyzeClick = async () => {
try {
setLoading(true);
const results = await analyzeImage(inputValue);
setAnalysisResults(results);
} catch (error) {
console.error(error);
} finally {
setLoading(false); // This ensures we set loading to false even if there's an error
}
};Respuesta de la API
La respuesta de la API es en formato JSON, aquí les dejo un ejemplo:
Full JSON:
{
"modelVersion": "2023-10-01",
"captionResult": {
"text": "a man in a blue jersey running on a field with a net and a crowd of people in the background",
"confidence": 0.7091192603111267
},
"metadata": {
"width": 889,
"height": 1186
},
"tagsResult": {
"values": [
{
"name": "person",
"confidence": 0.9974309206008911
},
{
"name": "sport",
"confidence": 0.9920082688331604
},
{
"name": "athletic game",
"confidence": 0.9869891405105591
...... other tags.....
]
},
"readResult": {
"blocks": [
{
"lines": [
{
"text": "ETIHAD",
"boundingPolygon": [
{
"x": 376,
"y": 418
},
{
"x": 519,
"y": 364
},
{
"x": 530,
"y": 391
},
{
"x": 387,
"y": 447
}
],
"words": [
{
"text": "ETIHAD",
"boundingPolygon": [
{
"x": 379,
"y": 419
},
{
"x": 501,
"y": 371
},
{
"x": 515,
"y": 397
},
{
"x": 393,
"y": 446
}
],
"confidence": 0.868
}
]
},
-....... OTher OCRs. .....
}
]
}
]
}
]
}
}Lo importante es que procesamos y devolvemos la información que en este caso nos interesa del analisis:
return (
<div>
<h2>Computer Vision Analysis Results</h2>
<img src={inputValue} alt="Analyzed content" style={{ maxWidth: '100%' }} />
{results.captionResult && (
<div>
<h3>Description:</h3>
<p>{results.captionResult.text}</p>
</div>
)}
{results.tagsResult && (
<div>
<h3>Tags:</h3>
<ul className="center-aligned-list">
{results.tagsResult.values.map((tag, index) => (
<li key={index}>{tag.name}</li>
))}
</ul>
</div>
)}
{results.readResult && (
<div>
<h3>Read Text:</h3>
<ul className="center-aligned-list">
{results.readResult.blocks.map((block, blockIndex) =>
block.lines.map((line, lineIndex) => (
<li key={`${blockIndex}-${lineIndex}`}>{line.text}</li>
))
)}
</ul>
</div>
)}
<button onClick={toggleJsonDisplay}>
{showJson ? 'Hide full JSON' : 'Show full JSON'}
</button>
{showJson && (
<div>
<h3>Full JSON:</h3>
<pre>{JSON.stringify(results, null, 2)}</pre>
</div>
)}
</div>
);
}
Dando la posibilidad de ver la respuesta completa en la ultima parte con el botón “showJson”
Leave a Reply