
Vamos a estar realizando una introducción a Azure Machine Learning. En esta oportunidad vamos a hacer una preparación basica del entorno y utilizar Sample data para realizar algunos cambios en un Data Asset utiilzando Pandas en Python.

¿Qué es Machine Learning?
Dentro de la Ciencia de Datos (Data Sience), ML es la disciplina que se encarga del entrenamiento y validación de los modelos predictivos. Tenemos datos, entrenamos al modelo y luego realizamos una inferencia.
Es un tipo de Inteligencia Artificial, que permite que las computadoras aprendan de los datos, identifiquen patrones, tomen decisiones y realicen predicciones de manera autónoma. Este aprendizaje se logra a través de diferentes enfoques y técnicas como Aprendizaje supervisado, no supervisado o reforzado (reinforce learning).
Está detras de los Chatbots, texto predictivo, aplicación de traducción de lenguaje, las sugerencias de tu streaming favorito o como tu feed de Instragram/Facebook/Twitter está presentado. Tambien es parte del software de vehiculos autónomos y es parte de herramientas de diagnostico en industrias medicas.
¿Qué es Azure Machine Learning?
Azure ML es un servicio de la nube que permite acelerar y gestionar el ciclo de vida de tus proyectos de Machine Learning. Tiene como objetivo ser usado por los AI engineres, ML Pros, Cientificos de Datos en las actividades del día a día para entrenartr y gestionar modelos. A las operaciones de ML se le llaman MLOps.
Está integrado y puede usar modelos Open Source como PyTorch, TensorFlow o Llama. Las herramientas de Azure ML permiten monitorear, re-entrenar y re-implementar los modelos.
Tiene diferentes herrmientas cross-compatible que permiten utiilzar interfaces como:
- AzureML Stuido.
- Python SDK.
- Azure CLI.
- ARM Restful APIs.
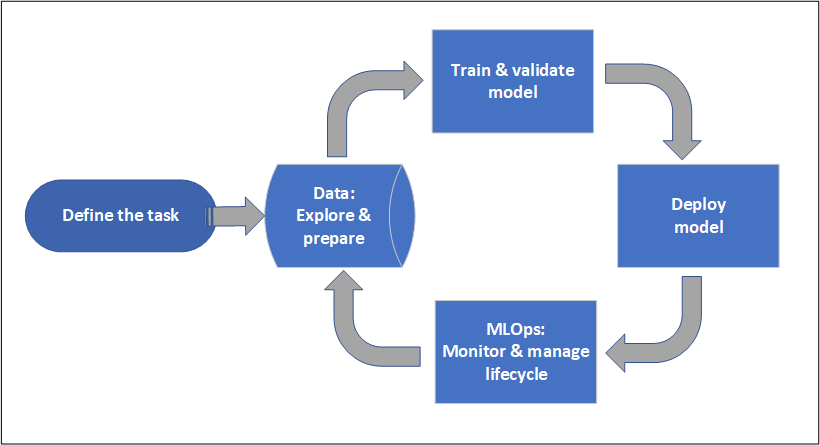
¿Qué son los Workspaces?
Los Espacios de Trabajo (o Workspaces) permiten organizar los Projectos de MLOps en Azure ML Studio. Permite diseñar un limite administrativo de trabajo y colaboración.
Permiten agrupar trabajo relacionado como experiments, jobs, datasets, models, components o inference endpoints.
Compute Instance en el contexto de Azure ML
Es una Workstation en la nube para gestionar los MLOps. El objetivo es que se utilice como el entro de Desarrollo con todos los prerrequisitos configurados de manera automatica y está Optimizado para ML. Nos permitirá utilizar Notebooks integrados con Jupyter y esta integrado de manera nativa con el Servicio.
Ademas nos permitirá reducir los riesgos de seguridad con politicas integradas. Podremos configurar Schedules para iniciar el computo solo cuando lo necesitemos.
Azure Machine Learning Studio
Es el portal en nuestro entorno de AzureML que nos permitirá gestionar todas nuestras MLOps, desde Compute hasta Pipelines y Data.
Algunas de las partes del Azure ML Studio:
- La sección de Authoring contiene:
- Notebooks donde podremos crear Jupyter Notebooks para ejecutar scripts.
- Automated ML para crear modelos sin escribir codigo.
- Designer donde encontraremos un drag-and-drop para construir nuestros modelos.
- La sección de Assets nos permite gestionar nuestros assets creados.
- En Manage podremos crear Compute y Servicios Externos. Acá tambien podremos gestionar el Data labeling.

Ahora vamos a iniciarnos en la creación y acceso a Azure ML.
Crear Recurso de Azure ML
Primero vamos a crear el Recurso de Azure ML. En este caso, creamos un Grupo de Recursos llamado AI102-Labs, ingresamos en el mismo y creamos un nuevo recurso.
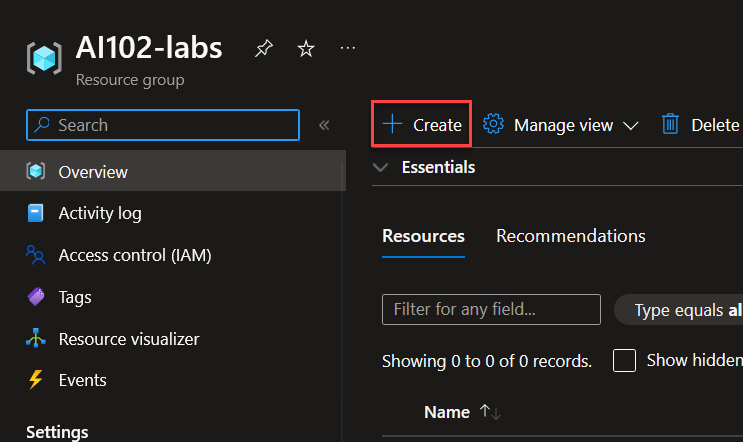
Buscamos Azure Machine Learning. Click en Create.
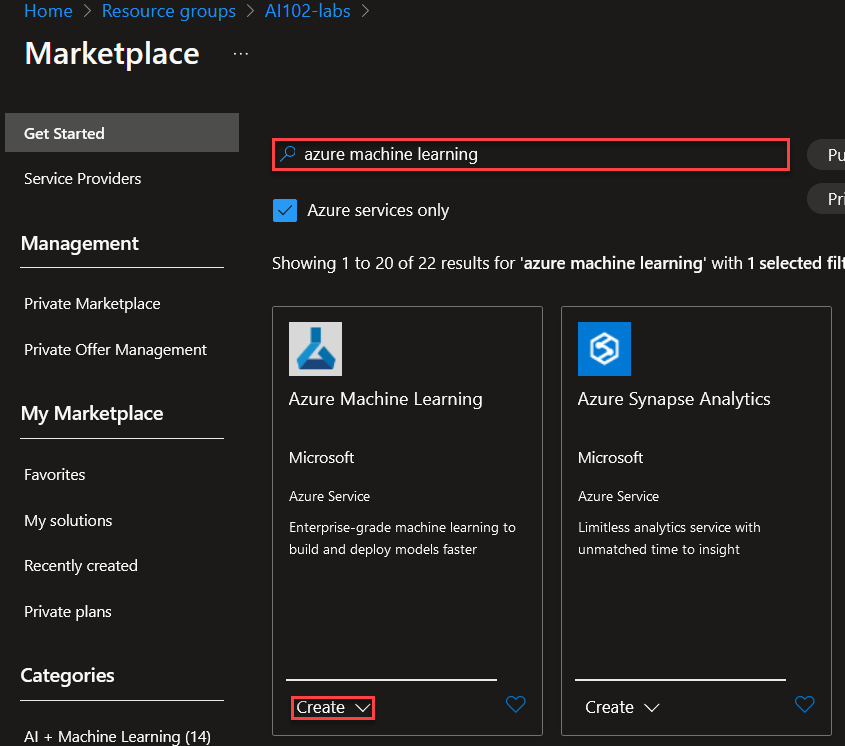
Vamos a asignar un nombre al recurso y dejaremos la creación automatica del resto de los recursos. Crearemos un nuevo ACR haciendo click en Create New.
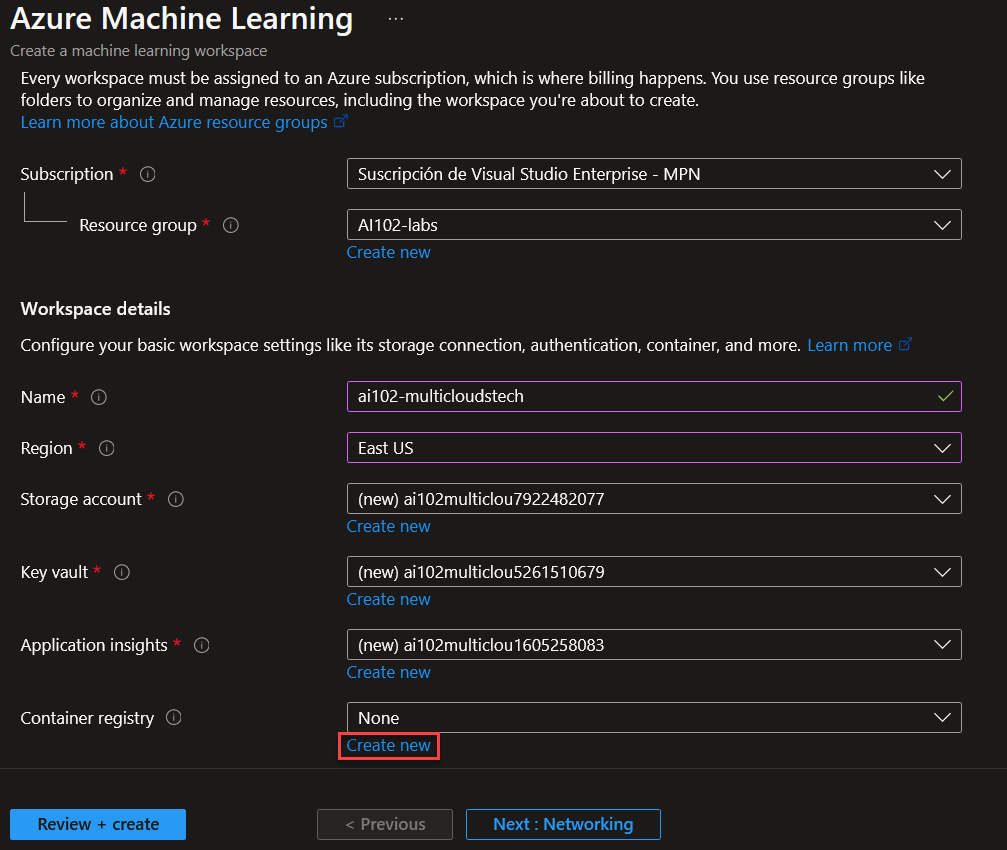
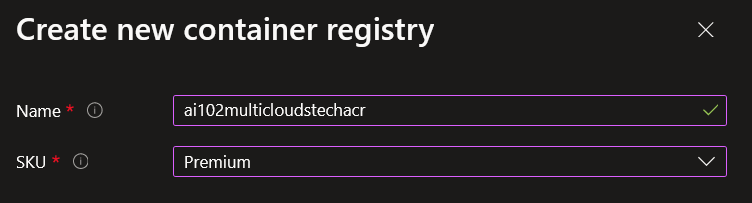
Asignamos un nombre al ACR y seleccionamos SKU premium. Click en Create.
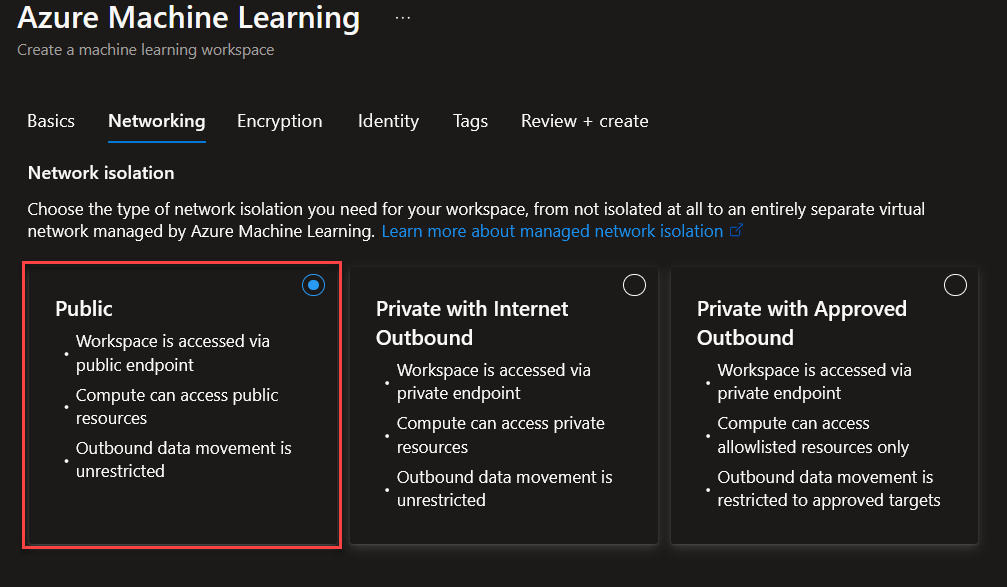
En Networking, seleccionaremos Publico por comodidad de la demo.
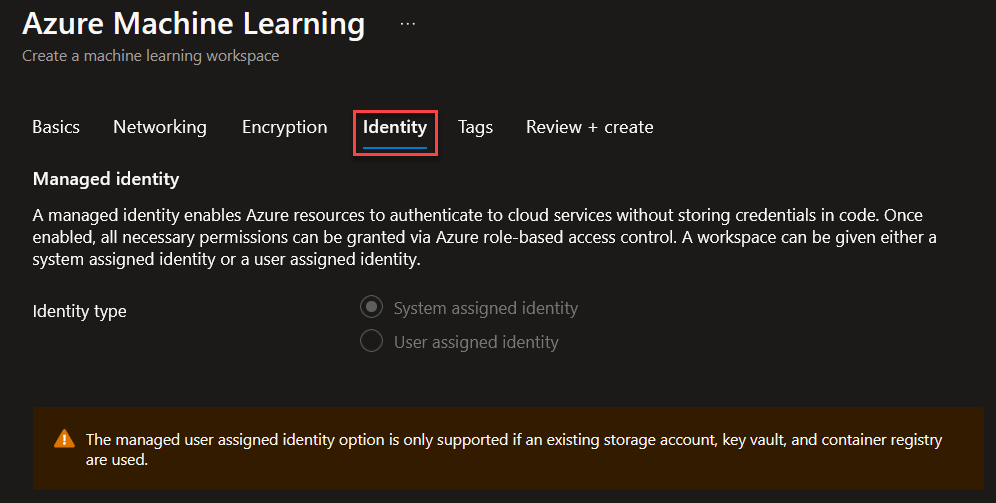
En identity no selecionamos nada.
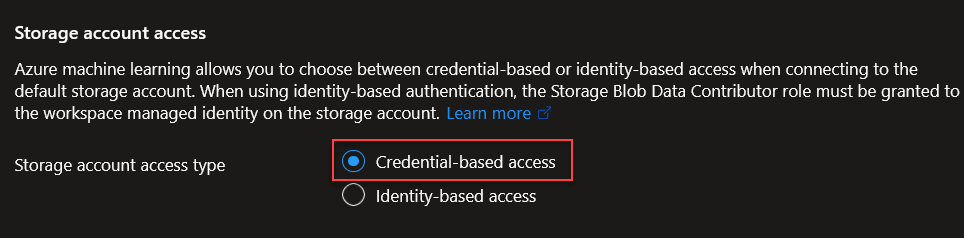
Y nos aseguramos de tener credential-based access.
El resto de las opciones las dejamos por default. Click en Create.
Verificamos que el deployment se realizó de manera correcta.
Una vez creado, ingresamos y hacemos click en Launch Studio.
Al acceder podremos ver el Azure ML Studio.
Verificamos estar en el Workspace.
Hacemos Click en Notebooks.
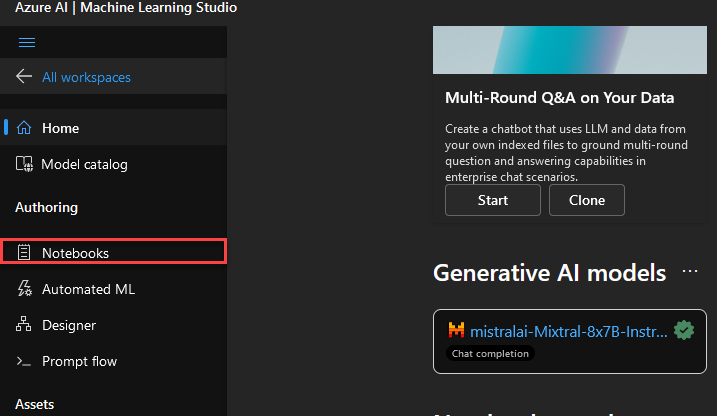
Click en Create Compute (esto solo estará disponible si no tenemos ninguna Compute instance creado).
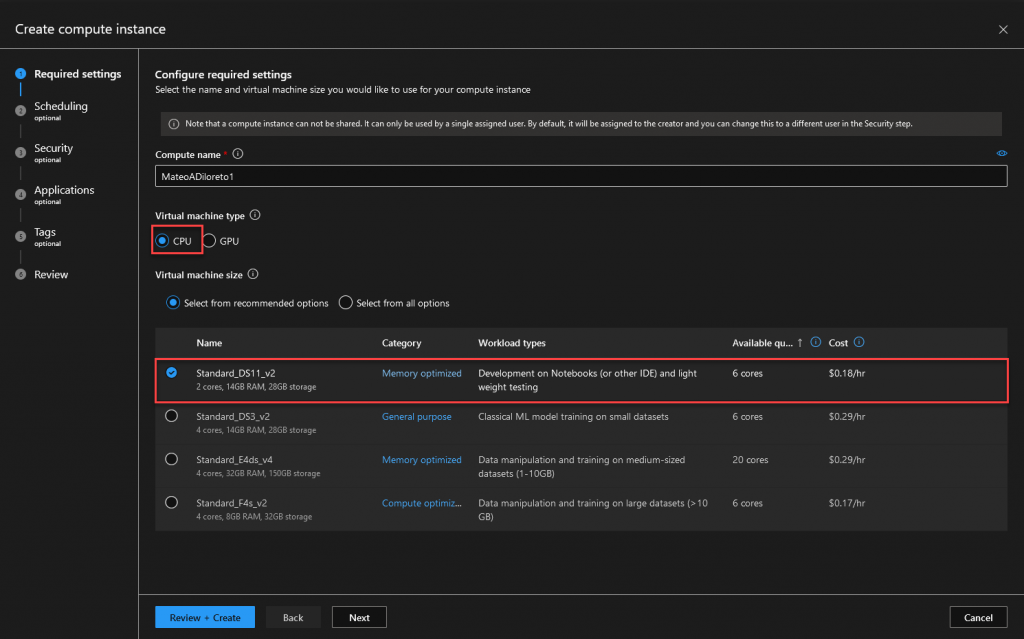
Seleccioanmos el SKU mas bajo. Click en Review + Create.
En Schedule, nos aseguramos que tenga idle Shutdown para ahorrar costo.
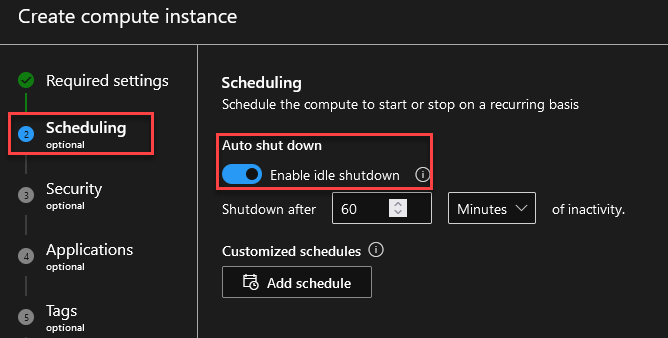
Asignamos Managed Identity.
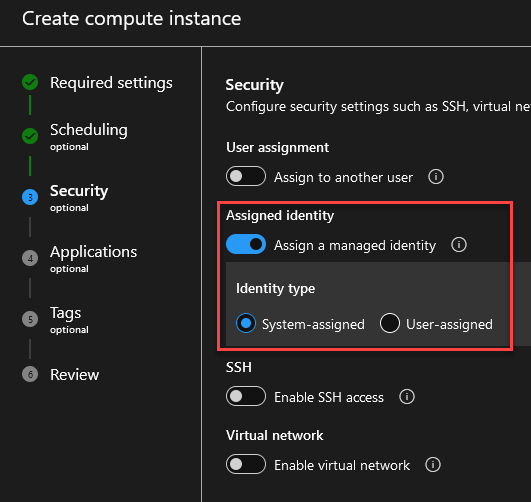
Review + Create.
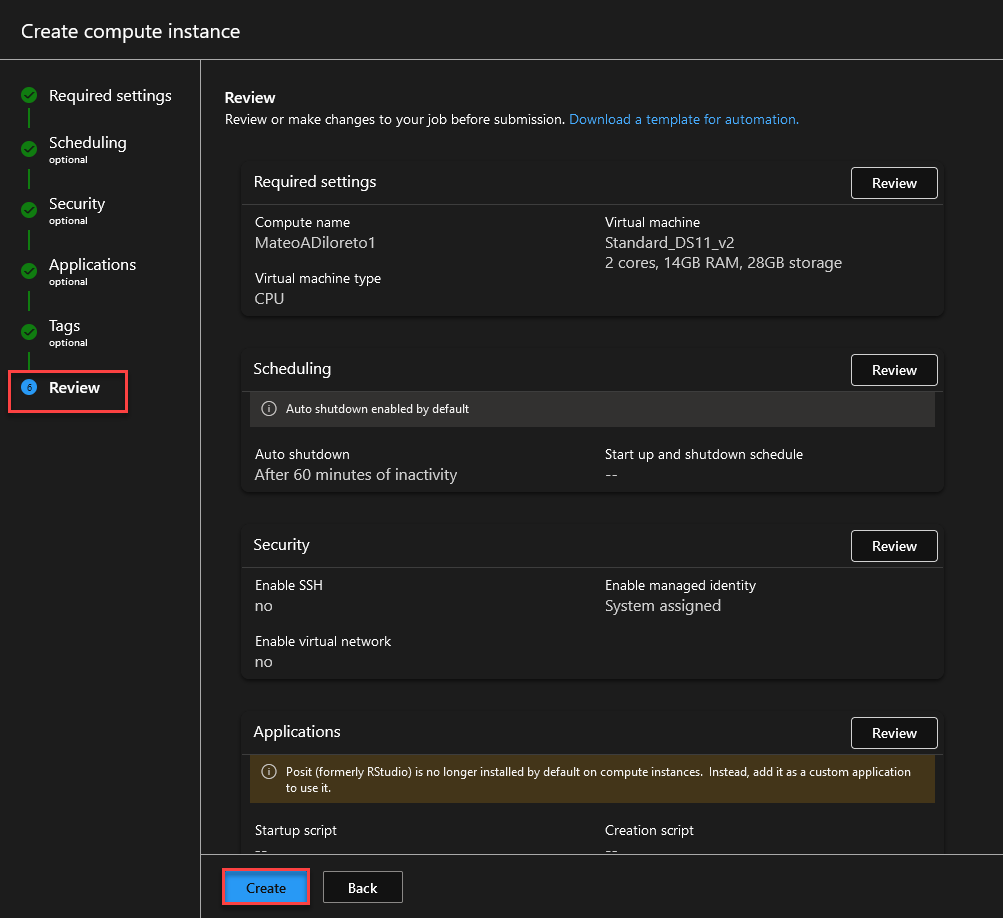
Ahora aguardamos a que se realice la creación.
Verificamos que se haya completado la creación.
Ingresamos a la Terminal.
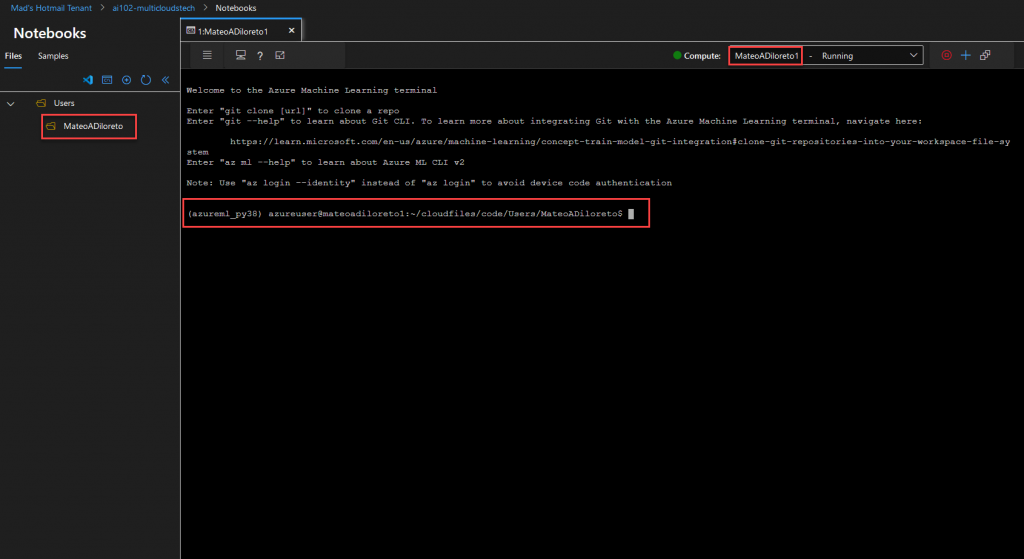
Así debería verse la terminal:
Ejecutar un Sample
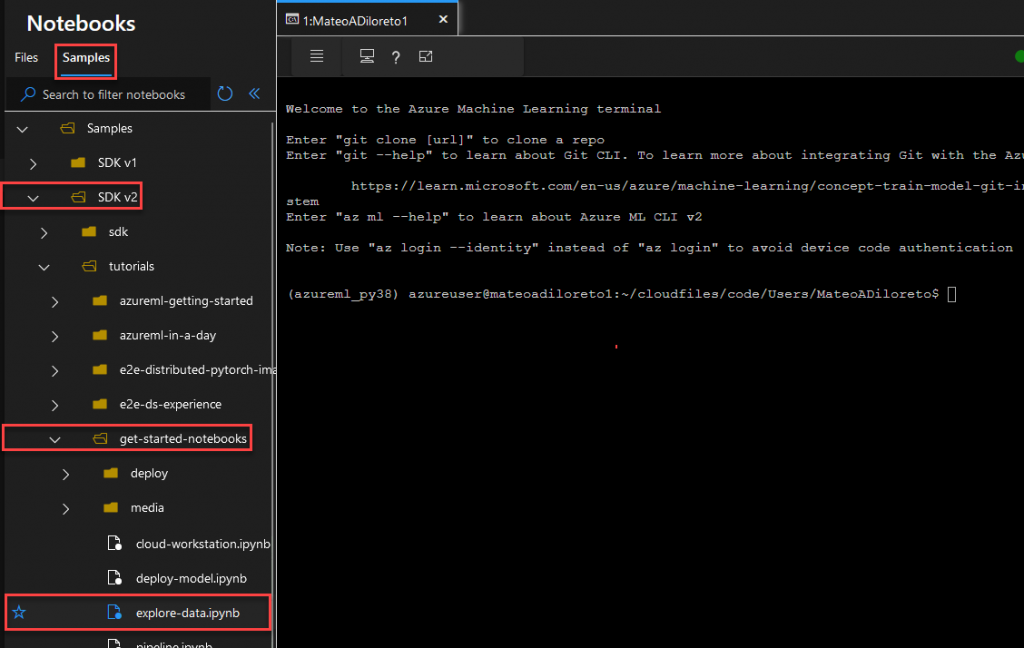
Ahora ejecutaremos unos de los Samples. Ingresamos en la Tab “Samples”, click en SDK v2, get-started-notebooks y hacemos click en el archivo “explore-data.ipynb”.
Se abrirá una nueva solapa de terminal. Hacemos click en “Clone…”
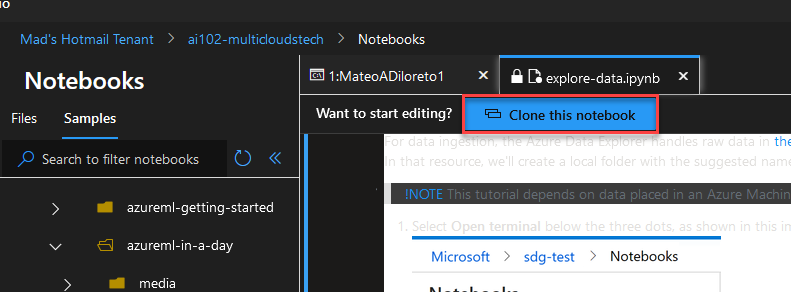
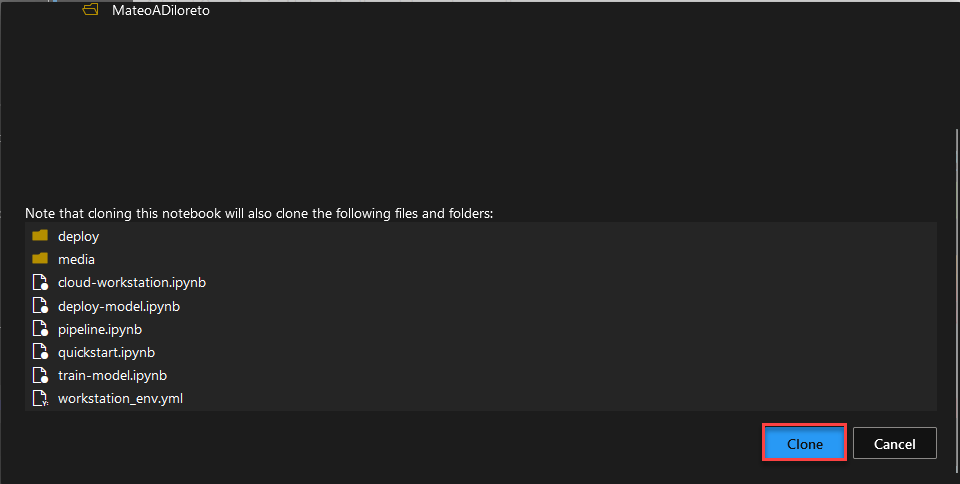
Clone
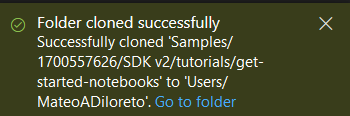
Veremos que la carpeta se clono correctamente.
Ahora veremos los archivos en nuestro root de Compute Instace.
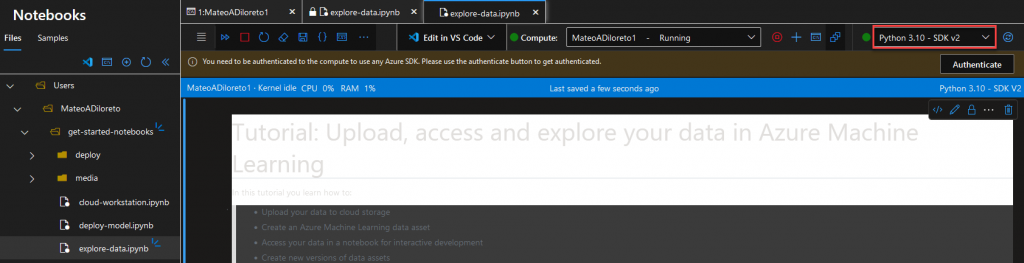
Volvemos a abrir la terminal, haciendo click en el icono señalado:
E ingresamos el siguiente codigo.
ls
cd get-started-notebooks
mkdir data
cd data
wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv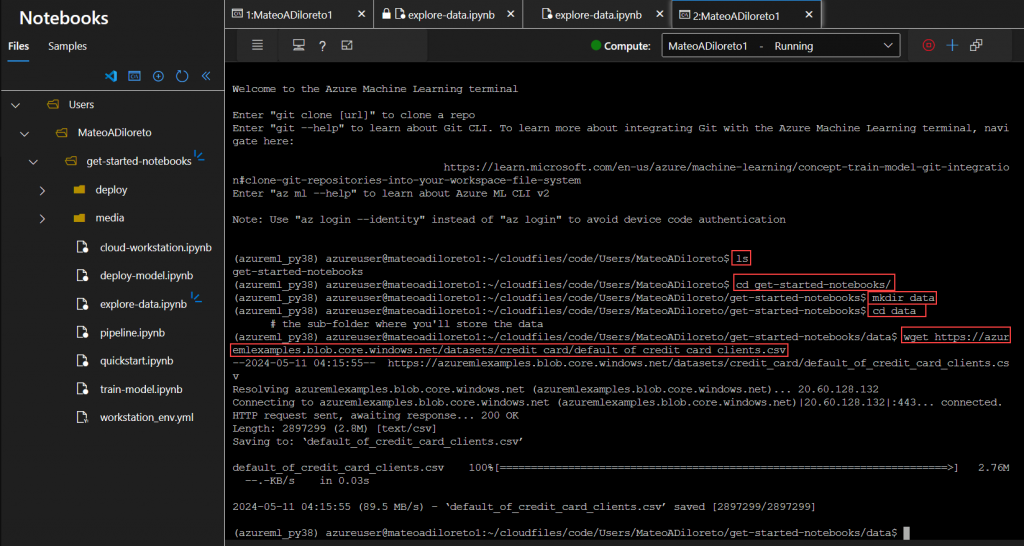
Esto nos descargaraá los achivos de Data.
Connect to Visual Studio Code (desktop)
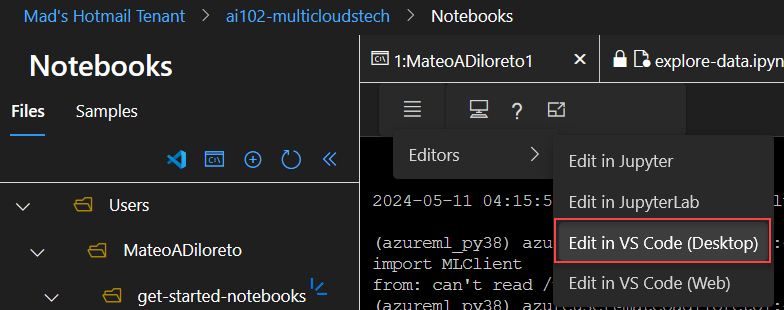
Ahora abriremos el VSCode Local. En Editors, buscar VSCode (Desktop).-
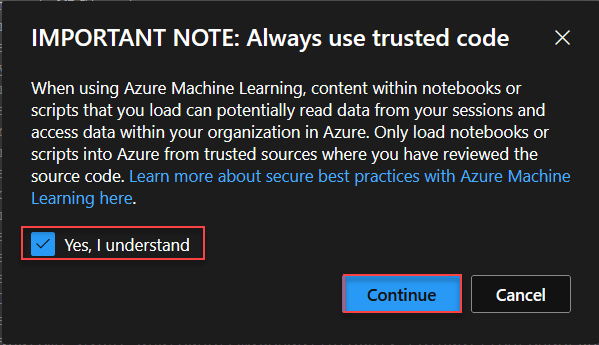
Hacer click en Yes y Continue.
Instalar extension.
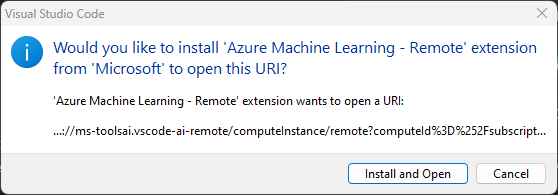
Realizar el Sign in en VSCode.
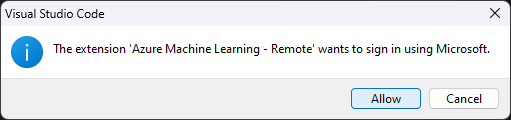
Ahora deberiamos tener el VSCode connectado.
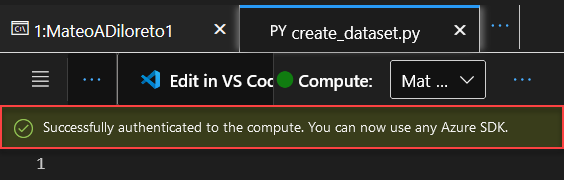
IMPORTANTE! Antes de ejecutar los scripts de Python debemos asegurarnos que nuestro Notebook este autenticado con el SDK. Esto lo realizaremos en el AML Studio
Ahora debemos generar un script con el siguiente codigo:
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
my_path = "./data/default_of_credit_card_clients.csv" ## Verify Path!
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")En mi caso, cuando intenté ejecutarlo desde la terminal, tuve que instalar el modulo azure.ai.ml con el siguiente commando:
pip install azure.ai.ml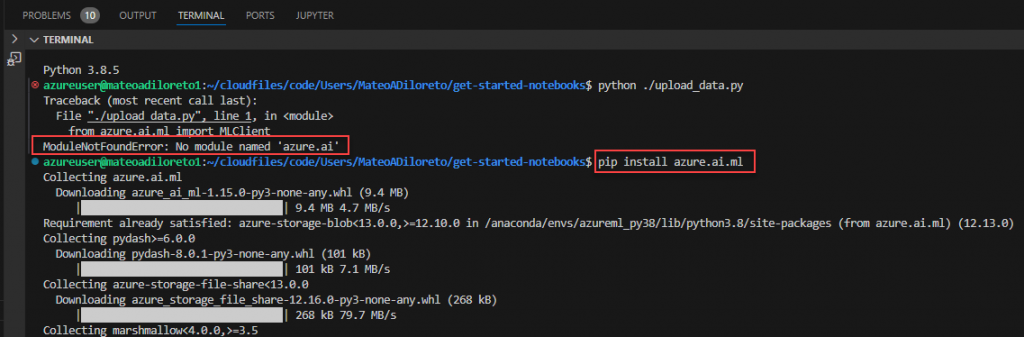
Ahora si, ejecutamos el archivo creado:

Verificamos que tenemos el Dataset creado en la sección de Data de nuestro AzureML Studio:
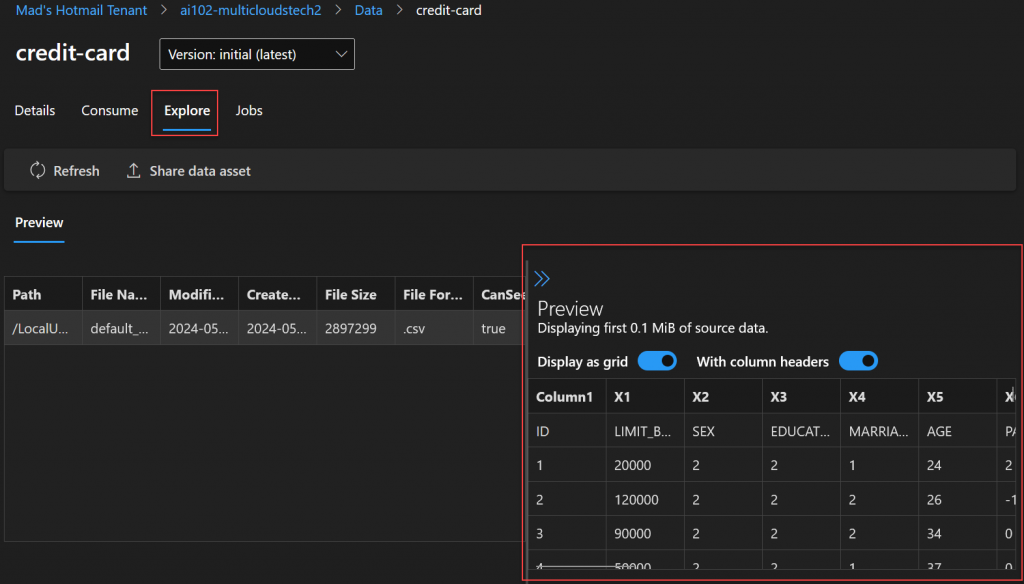
En la sección Explore podemos ver el contenido Preview de los datos.
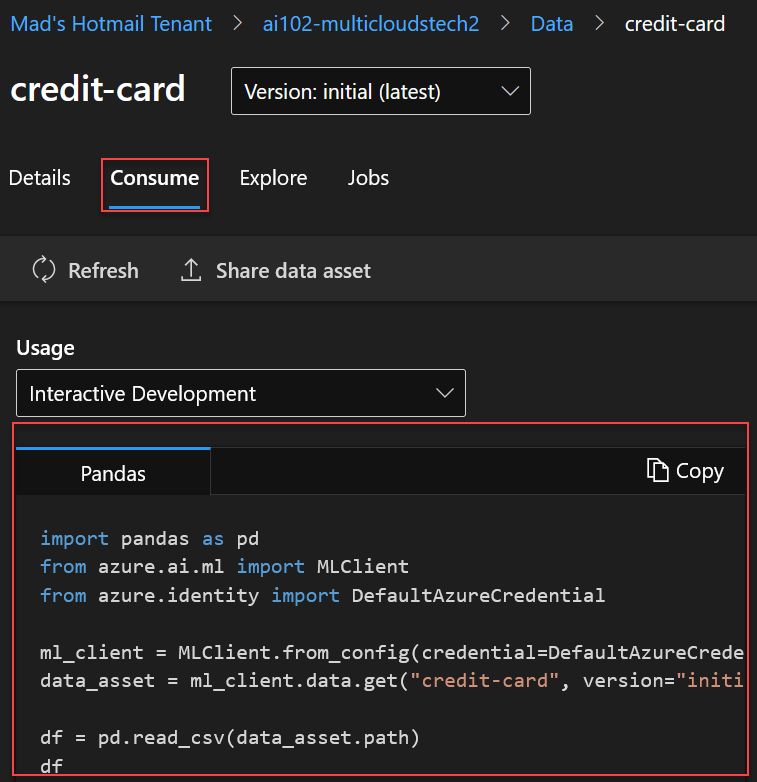
En la sección, Consume vamos a poder ver un codigo de ejemplo para consumir este Dataset utilizando Pandas:
Ahora vamos a crear un nuevo file en nuestro notebook llamado “tutorial-notebook.ipynb” para ejecutar el resto de nuestros comandos:
Vamos a ejecutar el siguiente código:
import pandas as pd
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get("credit-card", version="initial")
df = pd.read_csv(data_asset.path)
df
df.head()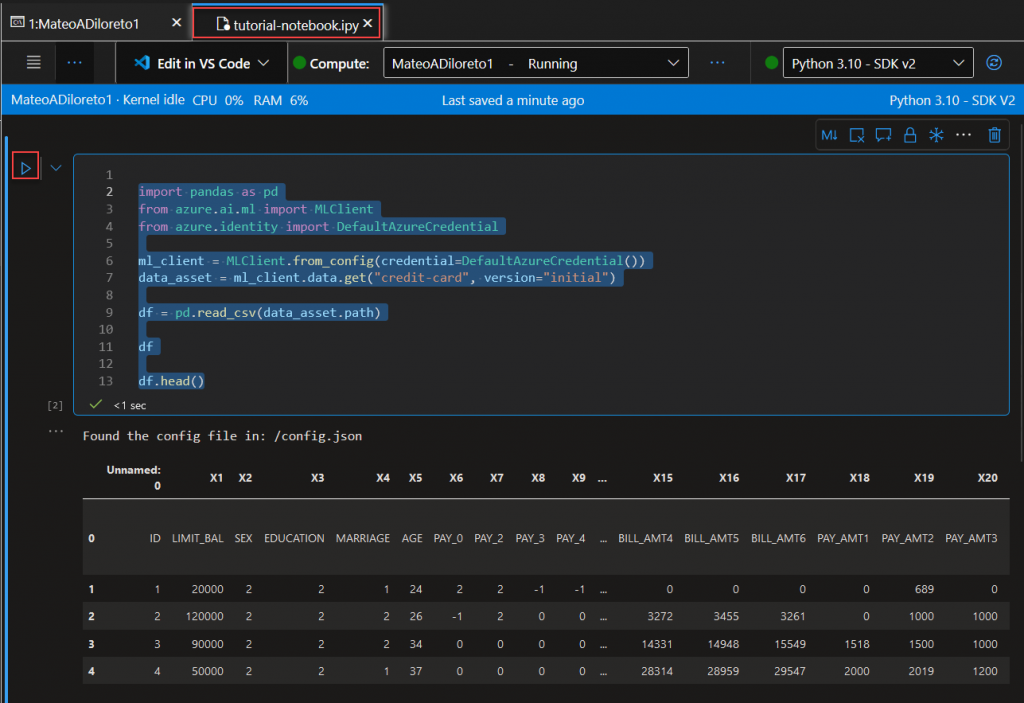
Crear una nueva version del dataset
Ejecutamos el siguiente script:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./get-started-notebooks/data/cleaned-credit-card.parquet")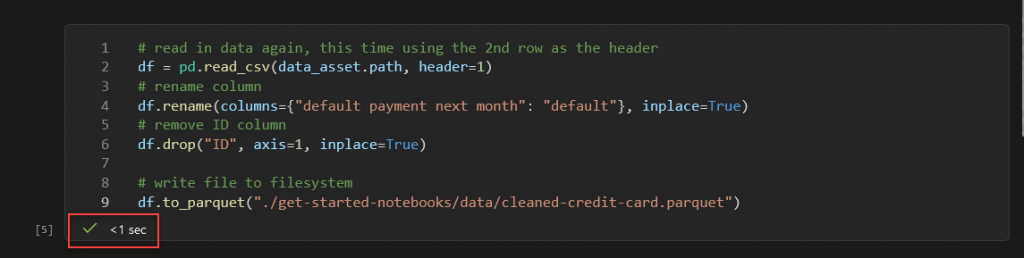
Y verificamos la creación del archivo .parquet.
Ahora creamos una nueva version de los datos basado en el parquet que creamos, utilizando el siguiente codigo:
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./get-started-notebooks/data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")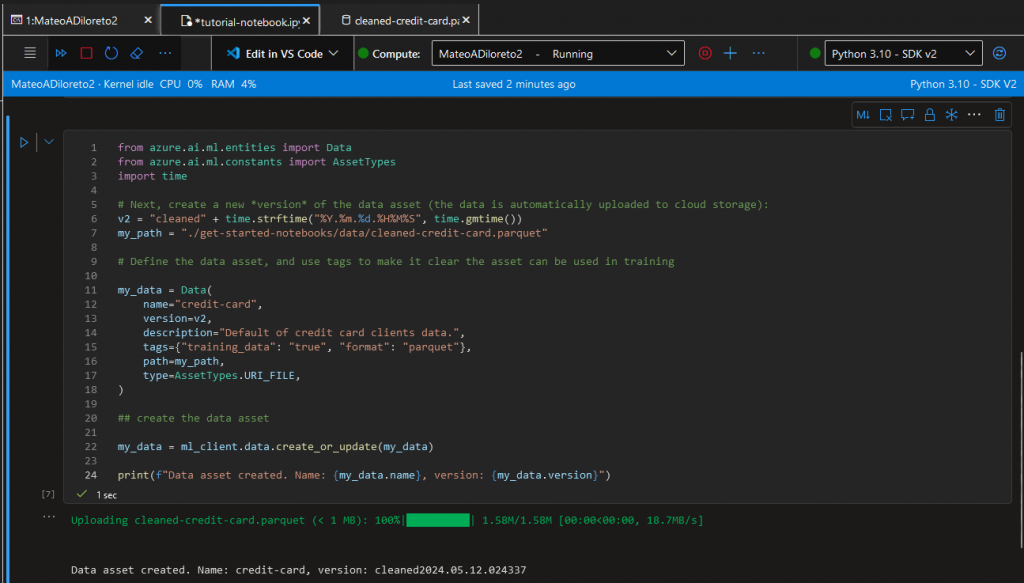
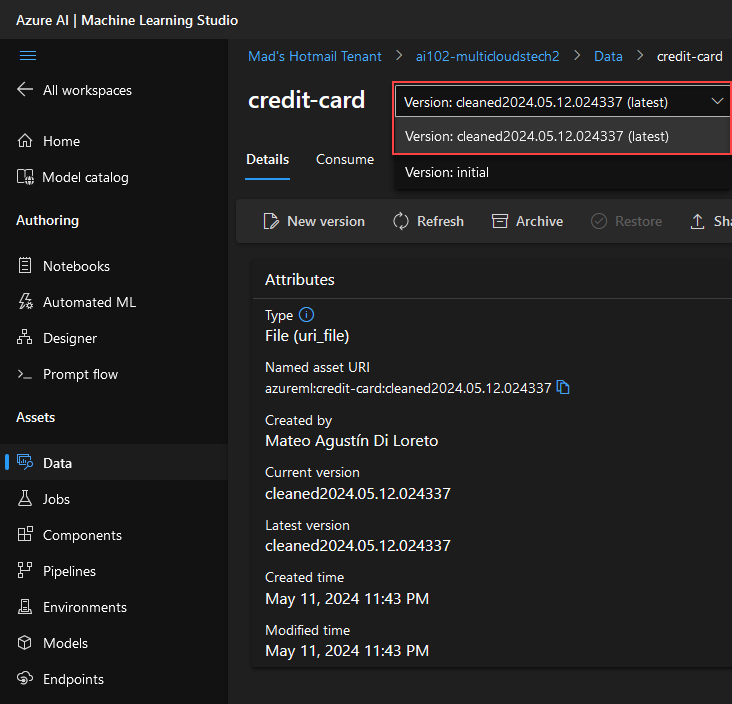
Verificamos que tenemos una nueva version:
Verificamos corriendo el siguiente codigo en nuestro Notebook, la comparativa entre los datasets:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version="initial")
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))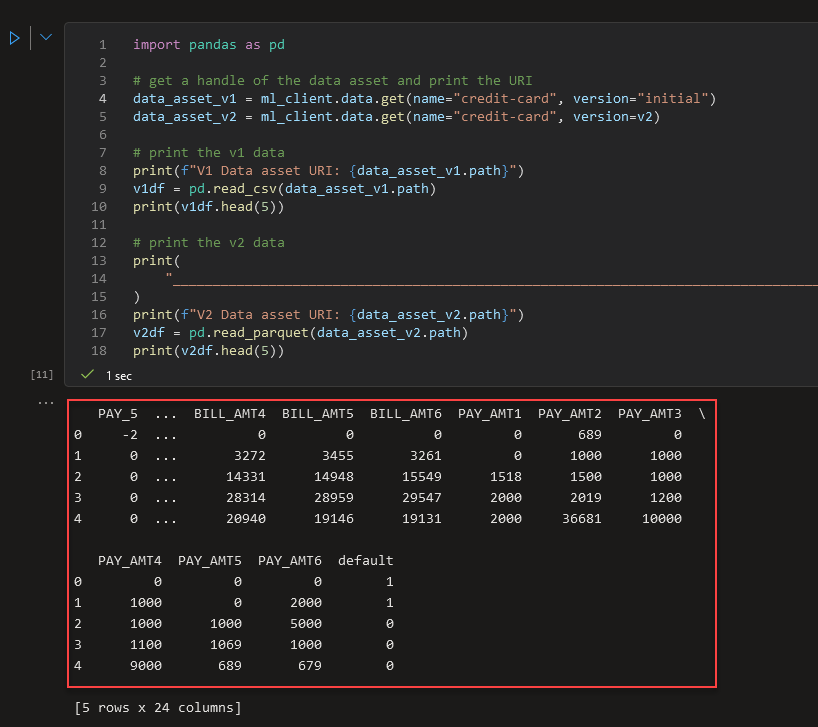
Leave a Reply